Part 2 – The Great Console Rewrite
Part 2 – The Great Console Rewrite
The 68K assembler version of the console had a peculiar architecture. When the console was opened, it allocated display memory 50% bigger than the size of the window (in those days the console had to be passed the address of an existing window when you opened it). That memory was divided up into a character map, Width by Height bytes, and a similar sized array of character attributes. The addressing of the array was really strange and I think it might have been translated into 68K assembler from BCPL.
The new console had to include:
1) A ReAction window and gadgets;
2) History and display scrolling;
3) Multiple windows (tabbed);
4) Menu;
5) Prefs Settings.
As I mentioned last time, the fixed array size made it impossible to add history features to the architecture. Also, any operation such as an insertion, deletion, window resize or refresh was implemented by unpacking the whole character map and repacking it again. It was designed for a particular architecture and was not adaptable. We decided to use a linked list for the display rows, so that rows could be added or deleted at any time without having to repack a large array. The rows were then allocated and returned to a memory Pool for speed. The independence of the rows made it easy to keep a few pointers to the list, such as “History Start”, “Display Start”, “Display End” and “History End”. Most list operations were simplified by this approach and scrolling speed seemed to be adequate.
The ReAction Window and Gadgets
The old console window was opened by the con-handler and its address passed to the console device. That meant that one program (the con-handler) opened and “owned” the window, but another (the console device) performed all the work on it. That had to change if we were ever going to support memory protection. In any case, it made sense that the program that used the window, opened and closed it also. One of the first changes was that the console device would from now on open and maintain its own window (of course, it still had to accept the address of an existing window passed to it by an old program).
Once the console could open its own window, it could make it a ReAction window with Iconify, Scroll and ClickTab gadgets. If it was passed the address of an existing window, then none of the “extras” could be added since the calling program might have added its own extras, so only “new-style” windows have all the extra gadgets. Now you no longer have to close the Shell when you change Workbench GUI settings!
Most of the gadgets can be independently enabled or disabled by options in the Shell tooltypes.
History and Display Scrolling
One feature of the old design was that a long row could overlap the edge of the display window and “wrap around” onto the next row. You’ve all seen what happens when you make a Shell window narrower – the long rows split into two or more and the text occupies more rows on the screen. To implement this feature with the linked list, we ended up creating “multiple rows” that consisted of two or more rows of text on the screen, but linked, each one to the others on each side. What is more, the new console display had to be able to scroll text on and off top and bottom of the window. The window might even have been resized since the old text was scrolled off the edge, so we had to accommodate changes in window width as old rows of text were scrolled back into view. A lot of work has gone into the treatment of “long lines”!
The current history, consisting of the contents of the linked list of lines, is stored in RAM. In order to save memory, we allow old history to be written out to a disk file once the number of lines of stored text reaches a predetermined limit. You can specify how many lines of text you want to keep in RAM, and what to do once that overflows (e.g. keep it in a disk file or discard it). You can also elect to save the whole Shell session to a file if you wish.
Scrolling the history is easy, you can use the mouse wheel, the scroll bar gadget or built-in keystrokes. If you have selected to write old history to backup files when the current buffer is full, you can even scroll back through the history that has been written to the file. As you do, that history is read back into the current buffer, making it exceed the size limit temporarily. If you like, you can display the number of lines of history in the window title.
Multiple Windows (Tabbed)
Adding a ClickTab gadget to the window makes it possible to switch the display between any one of two or more actual Shells. All Shells share the same window geometry and gadgets, but each has its own independent history and text attributes. You could have one Shell displayed in black on white, another in white on black and others in any combinations you like. When you switch from one Shell to another, the new one is displayed in its own colours and style. You can choose the text to be shown on each tab (you might like to have the current directory, for instance).
From one Shell, you can open a new one by selecting a menu item or a built-in keystroke. The new Shell is a clone of the previous one, that is, it “has” the same current directory, local variables, and so on. However, it is opened using the same “Shell-Startup” file as all the other Shells, so if your Shell-Startup file includes a line like “cd RAM:”, all new Shells will open with RAM: as the current directory.
You can close any Shell individually, or even all at once.
Menu
The menu accumulates all the key short-cuts (apart from those for command-line editing) and lets you select or edit settings as you wish. You can also call up the console Help file from the window. The Help file contains all the user documentation for the Shell, the con-handler and the console device. Most of the menu operations can also be performed by built-in keystrokes.
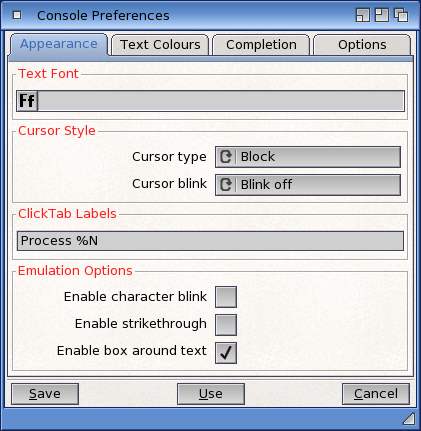
Prefs Settings
There is a Preferences Editor for the console settings. These are the default settings for the console and can be changed by the tooltypes in the Shell icon or the program running in the Shell window. You can also call the prefs editor from within the console window and “Use” the changes temporarily if you wish.
Appearance
You can select the font for the console text (fixed-width fonts only). You can also choose from a plain old “block” cursor, an underline or a vertical bar. You can make the cursor blink if you like.
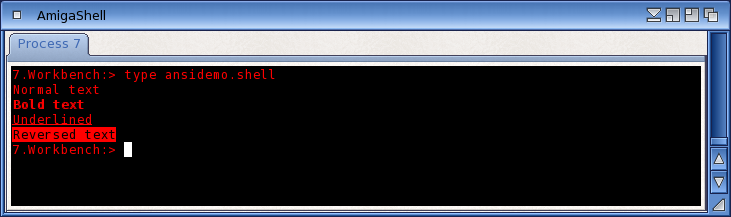
Text Colours
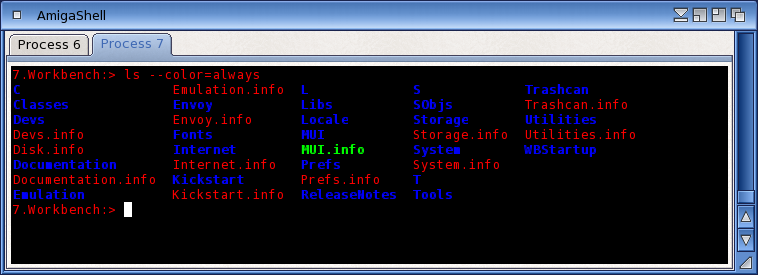
The “old” console was pretty restricted in its choice of text and background colours. You could use the ANSI escape sequences to set colours, but you could only choose from the system Pens. In the new console, we have introduced a palette of colours from which you can choose your text foreground and background colours. There are four palettes available to the user – you can select your preferred palette from the Preferences editor. The four palettes are the old System Pens, an ANSI set of primary colours, an ANSI set of “faint” colours and a “user” set which you can choose to your own preferences.
Text Attributes
The new console supports a few new text attributes, like italics, strike-through and character blink. Italics are spaced out slightly so that they don’t overlap with non-italic characters. The console does not attempt to support proportional fonts.
Name-Completion
Name completion strictly is a function of the con-handler, not the console, but it appears in the console window. You can now choose to have name-completion choices displayed in a “popup” window close to where you are typing. You can then choose from the displayed list. If you choose to see completion “in-line”, you can choose if or when you want the system to beep at you (if there are no matches, multiple matches, or “this is the last match”).
Another con-handler setting in the console prefs is the size of the command input buffer. The old console was fixed at 1024 characters, but now you can leave it at 16 kB or set it to anything up to 1 MB.
You can also change the default Tab spacing (Horizontal Tabs, not ClickTab) from its default eight spaces to two, or eleven, or any value between two and sixteen.
Compatibility with Older Programs
The new console works in either its “legacy” style or its “new” style, depending on how it is opened. While testing it, we have discovered several older applications that depended on unspecified console behaviour or even, in some cases, bugs in the old console.
We have tried to keep the new console compatible with the old, but inevitably there will be programs “out there” that will behave differently. Let us know and we will see what we can do.
New applications can use the newer console features and make the most of them.
Programmer Information
All the above description is user information, of course. The AmigaOS SDK contains the full documentation of the new console API. The AmigaOS Documentation Wiki has also been updated with new information about the improved Shell.
Well, that’s it for now. I hope you enjoy the benefits of the new Shell.